Sistem kecerdasan buatan (AI) yang bermain game telah maju ke garis depan baru. Stratego, game papan klasik yang lebih kompleks daripada catur dan Go, dan cerdik daripada poker, sekarang telah dikuasai.
DeepNash belajar untuk bermain Stratego dari awal dengan menggabungkan teori game dan deep RL tanpa model
Sistem kecerdasan buatan (AI) yang bermain game telah maju ke garis depan baru. Stratego, game papan klasik yang lebih kompleks daripada catur dan Go, dan cerdik daripada poker, sekarang telah dikuasai. Dipublikasikan di Science, kami menyajikan DeepNash, agen AI yang belajar game dari awal sampai tingkat ahli manusia dengan bermain melawan dirinya sendiri.
DeepNash menggunakan pendekatan baru, berdasarkan teori game dan pembelajaran refrensi tanpa model. Gayanya bermain akan convergen ke keseimbangan Nash, yang berarti cara bermainnya sangat sulit bagi lawan untuk dieksploitasi. Sangat sulit, bahkan, bahwa DeepNash telah mencapai peringkat tiga teratas sepanjang masa di antara ahli manusia di platform Stratego online terbesar di dunia, Gravon.
Game papan telah secara historis menjadi ukuran perkembangan dalam bidang AI, yang memungkinkan kita untuk mempelajari bagaimana manusia dan mesin mengembangkan dan mengeksekusi strategi dalam lingkungan yang terkontrol. Tidak seperti catur dan Go, Stratego adalah game informasi yang tidak sempurna: pemain tidak dapat langsung mengamati identitas piece lawan.
Kompleksitas ini berarti bahwa sistem Stratego berbasis AI lainnya telah kesulitan untuk maju di luar tingkat amatir. Ini juga berarti bahwa teknik AI yang sangat sukses yang disebut “pencarian pohon game”, sebelumnya digunakan untuk memahami banyak game informasi sempurna, tidak cukup scalable untuk Stratego. Karena alasan ini, DeepNash jauh melampaui pencarian pohon game secara keseluruhan.
Nilai dari penguasaan Stratego melebihi game. Dalam mengejar misi kami untuk menyelesaikan kecerdasan untuk memajukan ilmu pengetahuan dan membawa manfaat bagi umat manusia, kita perlu membangun sistem AI canggih yang dapat beroperasi di lingkungan kompleks dan nyata dengan informasi terbatas dari agen lain dan orang lain. Makalah kami menunjukkan bagaimana DeepNash dapat diterapkan dalam situasi ketidakpastian dan berhasil menyeimbangkan hasil untuk membantu menyelesaikan masalah yang kompleks.
Mengenal Stratego
Stratego adalah game menangkap bendera berbasis giliran. Ini adalah game tipuan dan taktik, pengumpulan informasi dan manuver halus. Dan itu adalah game zero-sum, sehingga setiap keuntungan yang diperoleh oleh salah satu pemain mewakili kerugian yang sama besar bagi lawan mereka.
Stratego sulit bagi AI, sebagian karena itu adalah game informasi yang tidak sempurna. Kedua pemain mulai dengan mengatur 40 mainan mereka dalam bentuk awal apa pun yang mereka sukai, awalnya tersembunyi satu sama lain saat permainan dimulai. Karena kedua pemain tidak memiliki akses ke pengetahuan yang sama, mereka perlu menyeimbangkan semua kemungkinan hasil saat membuat keputusan – memberikan benchmark yang menantang untuk mempelajari interaksi strategis. Jenis piece dan peringkat mereka ditunjukkan di bawah ini.
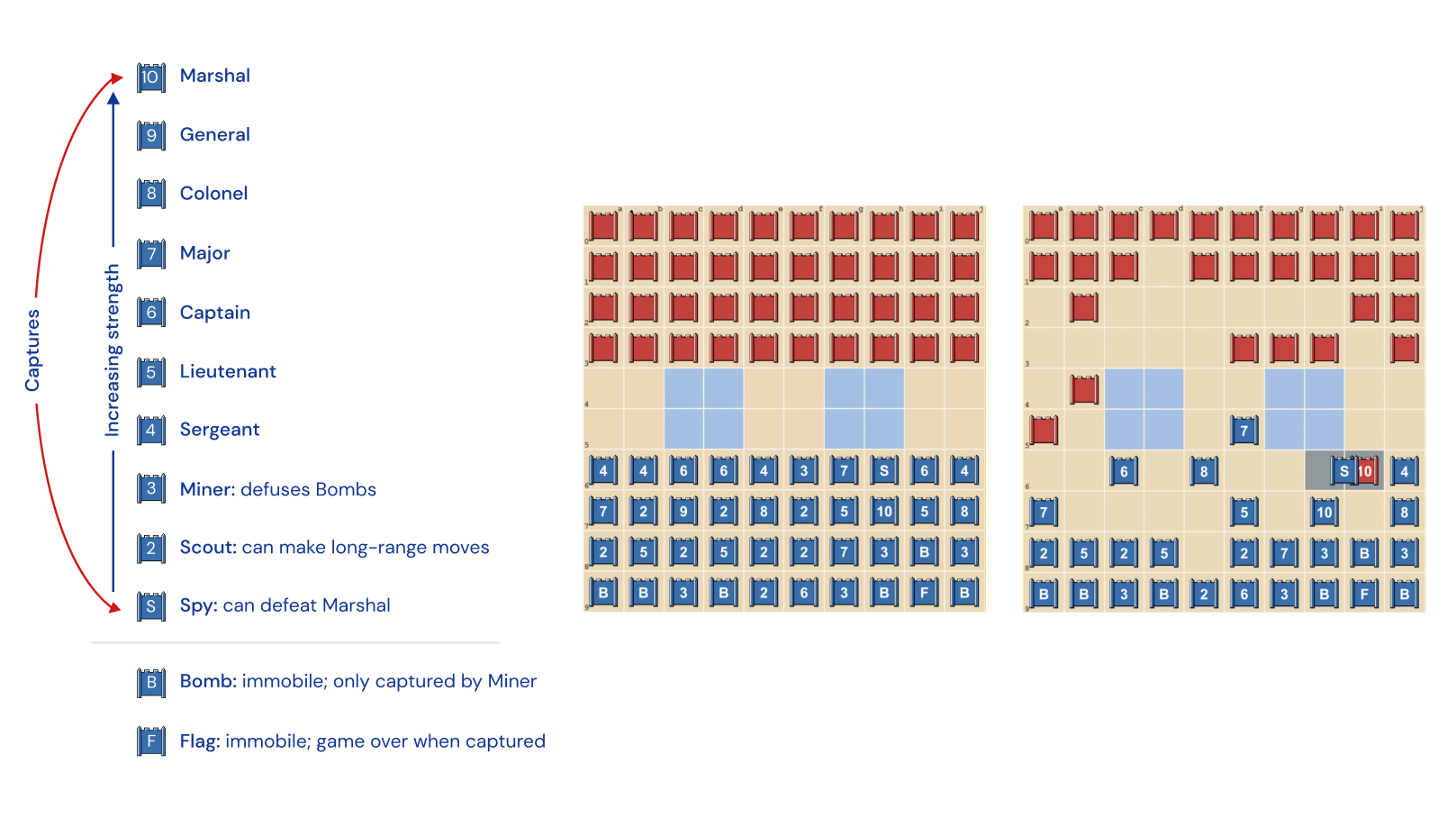
Tengah: Formasi awal yang mungkin. Perhatikan bagaimana Bendera terselip aman di belakang, disamping oleh Bom perlindungan. Dua daerah biru pucat adalah “danau” dan tidak pernah dimasuki.
Kanan: Game yang dimainkan, menunjukkan Spy Biru menangkap 10 Merah
Informasi sulit didapat dalam Stratego. Identitas piece lawan biasanya hanya terungkap saat bertemu dengan pemain lain di medan perang. Ini sangat berbeda dengan game informasi sempurna seperti catur atau Go, di mana lokasi dan identitas setiap piece diketahui oleh kedua pemain.
Metode pembelajaran mesin yang bekerja dengan baik pada game informasi sempurna, seperti AlphaZero DeepMind, tidak mudah ditransfer ke Stratego. Kebutuhan untuk membuat keputusan dengan informasi yang tidak sempurna, dan potensi untuk menipu, membuat Stratego lebih mirip dengan poker Texas hold’em dan memerlukan kemampuan seperti manusia yang pernah dicatat oleh penulis Amerika Jack London: “Hidup bukan selalu masalah memegang kartu yang baik, tetapi kadang-kadang, bermain tangan yang buruk dengan baik.”
Teknik AI yang bekerja dengan baik dalam game seperti Texas hold’em tidak dapat ditransfer ke Stratego, karena panjang game yang luar biasa – seringkali ratusan langkah sebelum pemain menang. Berpikir dalam Stratego harus dilakukan dalam jumlah besar tindakan sekuensial tanpa insight yang jelas tentang bagaimana setiap tindakan berkontribusi pada hasil akhir.
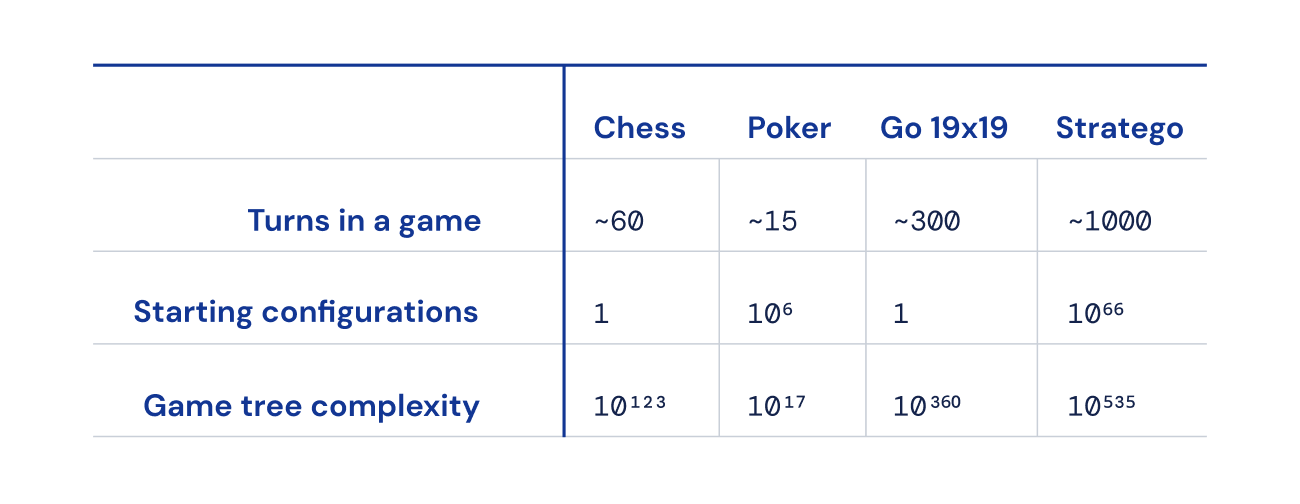
Akhirnya, jumlah keadaan game yang mungkin (diekspresikan sebagai “kompleksitas tree game”) sangat tinggi dibandingkan dengan catur, Go, dan poker, sehingga sangat sulit untuk diselesaikan. Inilah yang membuat kami bersemangat tentang Stratego, dan mengapa itu merupakan tantangan bagi komunitas AI selama beberapa dekade.
Mencari keseimbangan
DeepNash menggunakan pendekatan baru berdasarkan kombinasi teori game dan pembelajaran refleksi dalam. “Model-free” berarti DeepNash tidak mencoba memodelkan secara eksplisit keadaan game lawan selama game. Pada tahap awal game khususnya, ketika DeepNash sangat sedikit tahu tentang piece lawan, model seperti itu akan tidak efektif, bahkan mustahil.
Dan karena kompleksitas tree game Stratego sangat besar, DeepNash tidak bisa menggunakan pendekatan kuat dari AI berbasis gaming – Monte Carlo tree search. Pencarian tree telah menjadi bahan utama banyak prestasi terkemuka di AI untuk game papan yang lebih sederhana, dan poker.
Alih-alih itu, DeepNash diberdayakan oleh ide algoritma teori permainan baru yang kami sebut Dinamika Nash Teratur (R-NaD). Bekerja pada skala yang tak tertandingi, R-NaD mengarahkan perilaku belajar DeepNash ke arah yang dikenal sebagai keseimbangan Nash.
Perilaku bermain game yang menghasilkan keseimbangan Nash tidak dapat diimplementasikan dalam waktu yang lama. Jika seorang atau mesin bermain Stratego dengan sempurna tanpa dapat dieksploitasi, tingkat kemenangan terburuk yang dapat mereka raih adalah 50%, dan hanya jika menghadapi lawan yang sama sempurnanya.
Dalam pertandingan melawan bot Stratego terbaik – termasuk beberapa pemenang Piala Dunia Komputer Stratego – tingkat kemenangan DeepNash mencapai 97%, dan seringkali 100%. Terhadap pemain ahli manusia terbaik di platform game Gravon, DeepNash mencapai tingkat kemenangan 84%, menjadikannya salah satu dari tiga pemain teratas sepanjang masa.
Harapkan yang tak terduga
Pada fase penempatan pion, DeepNash menunjukkan perilaku yang luar biasa. Untuk menjadi sulit dieksploitasi, DeepNash mengembangkan strategi yang tidak terduga. Ini berarti menciptakan penempatan awal yang cukup beragam untuk mencegah lawan menemukan pola-pola dalam beberapa pertandingan. Dan selama fase permainan, DeepNash mengacak antara tindakan yang tampaknya sebanding untuk mencegah kecenderungan yang dapat dieksploitasi.
Pemain Stratego berusaha menjadi tidak terduga, sehingga ada nilai dalam menjaga informasi tersembunyi.
DeepNash menunjukkan bagaimana nilai informasi dapat ditunjukkan secara mencolok. Dalam contoh di bawah ini, terhadap pemain manusia, DeepNash (biru) mengorbankan, di antara elemen lainnya, 7 (Mayor) dan 8 (Kolonel) pada awal permainan dan sebagai hasilnya mampu menemukan 10 (Marsalis), 9 (Jenderal), 8, dan dua 7 milik lawan.
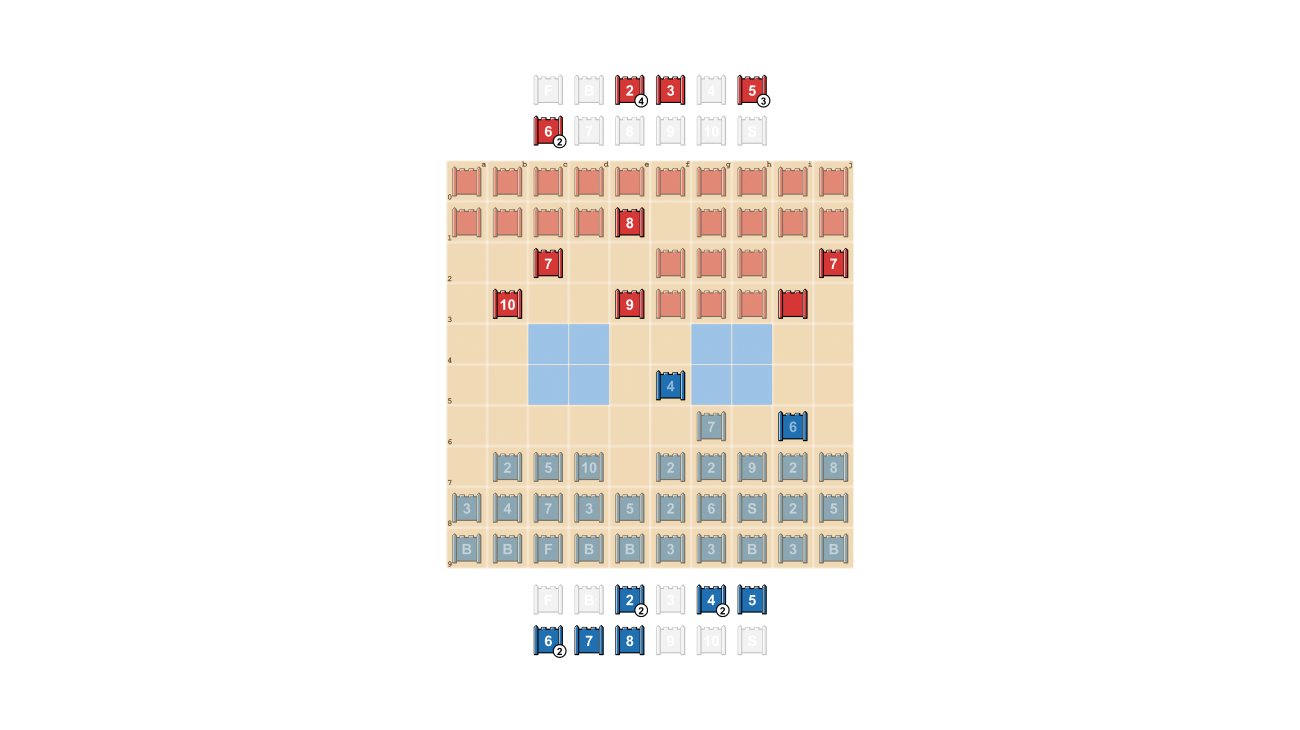
Upaya ini menyisakan DeepNash dalam keadaan kekurangan material yang signifikan; mereka kehilangan 7 dan 8 sementara lawannya manusia mempertahankan semua bagian teratas mereka. Namun, dengan informasi yang solid tentang bagian teratas lawannya, DeepNash menilai peluang menang mereka sebesar 70% – dan mereka menang.
Seni Menggertak
Seperti dalam permainan poker, seorang pemain Stratego yang baik harus kadang-kadang menunjukkan kekuatan, meskipun lemah. DeepNash belajar berbagai taktik bluffing. Dalam contoh di bawah ini, DeepNash menggunakan 2 (Scout yang lemah, tidak diketahui oleh lawannya) seolah-olah itu adalah sebuah benda yang memiliki ranking tinggi, mengejar 8 lawannya yang diketahui. Lawan manusia memutuskan bahwa pengejar tersebut kemungkinan besar adalah 10, dan dengan demikian mencoba menariknya ke dalam ambang kejaran oleh Spy mereka. Taktik ini oleh DeepNash, mengambil risiko hanya pada benda kecil, berhasil mengeluarkan dan menghilangkan Spy lawannya, benda yang kritikal.
Dalam arah masa depan
Meskipun kami mengembangkan DeepNash untuk dunia yang sangat terdefinisi dari Stratego, metode R-NaD yang baru kami gunakan dapat langsung diterapkan ke game zero-sum lainnya dengan informasi sempurna atau tidak sempurna. R-NaD memiliki potensi untuk meng-generalisasi jauh di luar setting game dua pemain untuk menangani masalah skala besar dunia nyata, yang sering ditandai oleh informasi yang tidak sempurna dan ruang keadaan astronomi.
Kami juga berharap bahwa R-NaD dapat membantu membuka aplikasi AI baru di domain yang memiliki banyak peserta manusia atau AI dengan tujuan yang berbeda yang mungkin tidak memiliki informasi tentang niat orang lain atau apa yang terjadi di lingkungan mereka, seperti dalam optimasi skala besar pengelolaan lalu lintas untuk mengurangi waktu perjalanan pengemudi dan emisi kendaraan yang terkait.
Dengan menciptakan sistem AI yang dapat di-generalisasi yang tangguh di hadapan ketidakpastian, kami berharap dapat membawa kemampuan pemecahan masalah AI lebih jauh ke dunia yang tidak dapat diprediksi secara alami kita.
Terjemahan bebas dari sini:
ttps://www.deepmind.com/blog/mastering-stratego-the-classic-game-of-imperfect-information
Leave a Reply